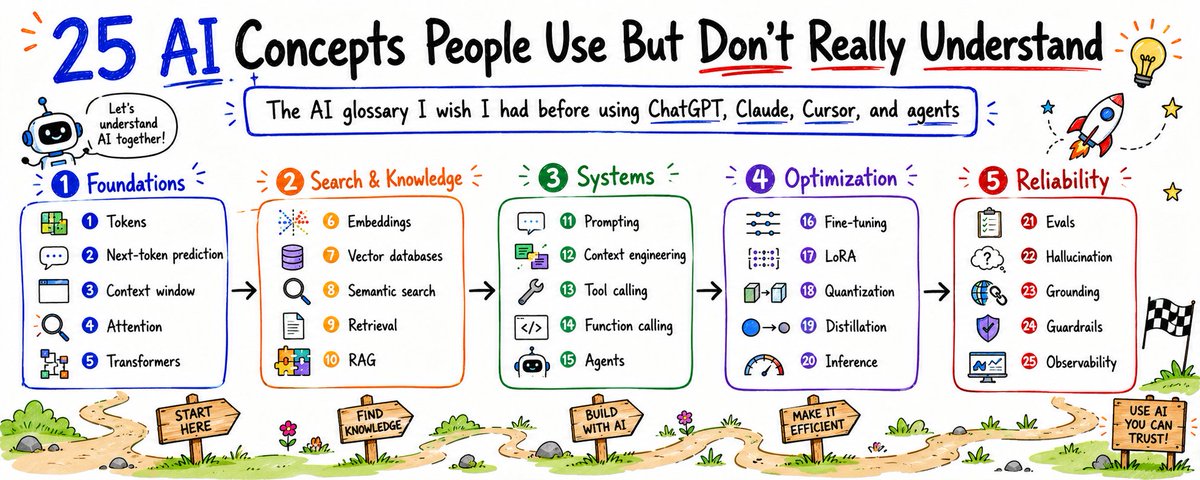
# 25 AI Concepts People Use But Don't Really Understand
> **Author**: [@techNmak](https://x.com/techNmak)
> **Published**: 2026-05-25
> **Source**: https://x.com/techNmak/status/2058886981090951627
AI became mainstream before most people understood its vocabulary.
That is why so many conversations around AI sound confident but fuzzy. People say "tokens," "embeddings," "RAG," "agents," "LoRA," "evals," and "guardrails" as if everyone shares the same definition.
Most of the time, they do not.
And that gap matters, because these are not just fancy terms. They are the parts of the machine.
> If you misunderstand tokens, you misunderstand context.
> If you misunderstand embeddings, you misunderstand semantic search.
> If you misunderstand RAG, you overestimate what retrieval can fix.
> If you misunderstand agents, you confuse autonomy with a loop.
> If you misunderstand evals, you end up judging AI systems by vibes.
So I wanted to write the kind of guide I would actually bookmark.
Clear enough for beginners. Accurate enough for builders. Useful enough to come back to later.
Here are 25 AI concepts that make modern AI much less confusing.
## 1. Tokens
**The first thing to understand about LLMs is that they do not process text exactly the way we read it.** They process tokens.
A token can be a full word, part of a word, punctuation, whitespace, or a special symbol. That is why one word does not always equal one token.
**This small detail affects almost everything** - context length, cost, latency, truncation, and generation. When you send a prompt, the model does not see "a paragraph" the way you do. It sees a sequence of token IDs.
That sequence is the raw material the model works with. So before understanding context windows, pricing, or generation, you have to understand tokens. They are the smallest practical unit of the system.
## 2. Next-token prediction
**At the core, a language model keeps asking one question** - what token should come next?
**It reads the current context and produces a probability distribution over possible next tokens.** One token is selected, added back into the context, and then the model repeats the process. That is how a full answer appears, not all at once, but one token at a time.
This is also why the same prompt can sometimes produce different answers. The model may assign probability to many reasonable continuations. The decoding strategy decides which path gets taken.
**Temperature controls how sharp or flat that probability distribution becomes.** Lower temperature makes the model more conservative. Higher temperature makes it more varied, but sometimes less stable. Top-k limits sampling to the k most likely tokens. Top-p, also called nucleus sampling, keeps the smallest set of tokens whose combined probability crosses a chosen threshold.
These settings do not change what the model has learned. They change how the model chooses from what it already believes is possible.
So when an answer feels like writing, remember what is happening underneath - the model is growing a sequence, step by step.
## 3. Context window
**The context window is the information the model can use for one run.**
It can contain the system prompt, user message, conversation history, retrieved documents, tool results, memory snippets, examples, and constraints. But context is often misunderstood.
**A bigger context window is useful, but it is not automatically better.** If you give the model messy, stale, duplicated, or irrelevant information, the problem does not vanish. You have only moved the problem into the prompt.
There is also a quality effect: information buried in the middle of very long contexts can be attended to less reliably than information near the beginning or end.
The better mental model is this: context is working memory. It's not a storage, or truth, or permanent knowledge. Just the information available to the model right now.
Good AI systems are careful about what enters that space. They do not just stuff everything in and hope the model figures it out.
## 4. Attention
Attention is one of the ideas that made modern language models work at scale.
**The simple version: tokens can weigh information from other tokens.** That lets the model build context-sensitive representations. "Bank" near "river" should behave differently from "bank" near "loan." Attention helps create that difference.
But for modern decoder-only LLMs, there is an important constraint: causal self-attention. Each token can attend only to previous tokens, not future ones. That future-token mask is what preserves autoregressive generation. The model cannot look ahead at tokens it has not generated yet.
So attention is not "the model understanding like a human." It is a mechanism for routing information across the visible context. Powerful, but still a mechanism.
## 5. Transformers
**Transformers are the architecture behind most modern text LLMs.**
The original breakthrough was making attention the central operation instead of relying on recurrence or convolution for sequence modeling. A transformer block usually combines attention, feed-forward layers, residual connections, and normalization. Stack many of these blocks, train at scale, and you get the backbone of modern language models.
One nuance matters - transformers can process input tokens in parallel during training and prompt processing, but generation is still autoregressive. The model still produces output token by token.
So "Transformer" is not one model or one company's product. It is an architecture family, and it is the reason modern LLM scaling became practical.
## 6. Embeddings
**Embeddings turn data into vectors.**
Text can become a vector. Code can become a vector. Images and audio can become vectors too. The useful property is similarity: if two pieces of content are related, their vectors may land close together.
That is what makes semantic search possible. A query like "how do I make my site faster?" can match a document about "page load optimization" even without exact word overlap.
But embeddings are not magic meaning. They are learned representations. They preserve some relationships and lose others.
A good embedding model for product search may not be ideal for legal documents. A good embedding model for English support docs may not be ideal for code.
The real question is not: are we using embeddings?
The real question is: are these embeddings useful for this task?
## 7. Vector databases
**A vector database stores embeddings and retrieves nearby vectors efficiently.**
The common flow is simple: split documents into chunks, create embeddings, store them with metadata, embed the user query, search for nearby vectors, and return likely matches.
That sounds clean. The messy part is everything around it.
How were the documents chunked? Was metadata preserved? Are outdated documents filtered out? Are permissions respected? Are exact terms handled? Are results reranked?
A vector database is not a brain. It does not know whether a document is true. It does not know whether a policy changed yesterday. It returns candidates based on vector similarity and whatever filtering logic you built around it.
Useful infrastructure. Not a complete AI system.
## 8. Semantic search
Keyword search matches words. Semantic search matches meaning-like representations.
That is why it can retrieve useful results even when the user and the document use different wording. This is a big deal, because people rarely ask questions in the exact language your documentation uses.
But semantic search is not always better than keyword search. Sometimes exact terms matter: error codes, API names, legal clauses, version numbers, product SKUs.
In those cases, pure semantic search can miss what keyword search catches.
This is why many strong retrieval systems use hybrid search. Semantic search gives flexibility. Keyword search gives precision. Metadata gives constraints. Reranking improves order.
Search is not one trick. It is a pipeline.
## 9. Retrieval
Retrieval means bringing external information into the system at query time.
This exists because language models have limits. They cannot see your private data unless you provide it. They do not automatically know what changed after training. They cannot fit an entire knowledge base into every request.
Retrieval is how the system finds relevant evidence before the model answers. But retrieval is not just "search the docs." It includes chunking, indexing, filtering, ranking, reranking, permissions, freshness, and context construction.
A lot of bad AI answers are not caused by the model being weak. They happen because the model was given weak evidence: wrong chunk, missing chunk, too many chunks, outdated chunk, or no source trail.
Retrieval quality often decides answer quality before the model even starts writing.
## 10. RAG
RAG stands for Retrieval-Augmented Generation.
The basic idea is simple: retrieve relevant information first, then generate an answer using that information. This separates two jobs. The retriever finds evidence. The generator turns that evidence into an answer.
That is why RAG is useful for private documents, fresh information, source-grounded answers, and domain-specific knowledge.
But RAG is also one of the most overused words in AI. It is not just "chat with PDFs." It is not a guaranteed hallucination fix. It does not make bad documents reliable. It does not make weak retrieval good.
RAG works when the right evidence is retrieved, ranked, placed into context, and used correctly. Bad retrieval still gives bad answers.
**RAG is not a truth machine. It is a design pattern.**
## 11. Prompting
Prompting is the instruction layer.
It tells the model what you want, what role it should take, what format to follow, what constraints matter, and what examples to imitate. A good prompt can make a huge difference.
But prompts are not spells. They do not update model weights. They do not add missing knowledge. They do not fix broken retrieval. They do not make unsafe tools safe. They do not replace evaluation.
That is where many beginners get stuck. They keep trying to solve system problems with better wording.
Sometimes the prompt is the issue. Often, the issue is the data, retrieval, tools, context, permissions, or evals.
Prompting matters, but it is one layer, not the whole system.
## 12. Context engineering
Context engineering is deciding what the model should see.
That includes the prompt, but also retrieved documents, conversation history, tool outputs, user state, memory, examples, policies, and intermediate work. The model can only operate on the tokens it receives, so the content, order, quality, and freshness of those tokens matter a lot.
This is why "just use a longer context window" is not enough. Long context gives you capacity. Context engineering gives you relevance.
A good system asks: what is useful right now? What is stale? What should be summarized? What should be retrieved? What should be hidden? What could confuse the model?
In serious AI systems, context becomes an engineering surface. Not an afterthought.
## 13. Tool calling
Tool calling lets a model interact with external systems.
A model can request a calculator, database, search engine, code runner, file lookup, calendar, CRM, or API. But the model usually does not execute the tool directly. The application does.
The model proposes a tool call. The system validates it. The application executes it. The result is sent back to the model.
That separation matters because it keeps permissions, data access, and side effects under software control.
A tool call is not proof that the action happened. It is a request. The app still owns validation, authorization, execution, retries, and error handling.
The model can ask. The system must decide.
## 14. Function calling
**Function calling is structured tool calling.**
Instead of returning loose text, the model returns arguments that match a schema. For example: function get_weather, location Mumbai, unit celsius.
That structure makes software easier to parse, validate, route, test, and reject. This is why function calling matters in production systems.
Free-form text is flexible. Structured output is controllable.
But the same rule still applies: a function call does not mean the function already ran. It is a structured request. The application still decides whether and how to execute it.
Schema first. Execution second. That is the production mindset.
## 15. Agents
"Agent" is one of the most stretched words in AI.
The practical way I think about it: an agent is a system that can loop. It can plan, call tools, observe results, update state, and decide what to do next.
That loop is what makes it different from a single prompt-response interaction. But autonomy is a spectrum. Many useful agents are not fully autonomous. They are bounded systems with limited tools, narrow goals, clear stop conditions, and human approval for risky actions.
That is often better.
Also, an agent does not automatically remember everything across sessions. Persistent memory has to be explicitly designed: what to store, when to retrieve it, how to update it, and when to ignore it.
A good agent is not powerful because it can do anything. It is useful because it can do the right thing within the right boundaries.
The hard part is not giving the model tools. The hard part is controlling how those tools are used.
## 16. Fine-tuning
Fine-tuning changes the model. Prompting changes the input.
That one distinction clears up a lot.
Fine-tuning starts with a pretrained model and continues training it on examples from a narrower task or domain. It can help with repeated patterns: tone, terminology, classification, formatting, domain-specific behavior, or task execution.
But fine-tuning is not the answer to every AI problem. If the model lacks fresh knowledge, retrieval may be better. If the problem is output structure, prompting or function calling may be enough. If the issue is safety, you need guardrails and evals.
This is also where many people confuse fine-tuning with alignment. **A common assistant-building pipeline is:**
pretraining → supervised fine-tuning → reward modeling → RL optimization
Pretraining gives the model broad capability. Supervised fine-tuning teaches it to follow instructions using curated examples. RLHF then refines behavior using human preference feedback. RLAIF is a related idea where AI feedback replaces or supplements human feedback.
So the useful mental model is this: fine-tuning adapts behavior, instruction tuning teaches response format and compliance, and RLHF/RLAIF refine alignment. They are connected, but they are not the same thing.
## 17. LoRA
LoRA stands for Low-Rank Adaptation.
It is a parameter-efficient way to adapt large models. Instead of updating all model weights, LoRA freezes the base model and trains small low-rank matrices inside selected layers.
That reduces the number of trainable parameters dramatically. Less memory, less compute, faster experimentation.
The base model stays mostly intact. The adapter carries the task-specific change. This is why LoRA became so popular in open-source model workflows. It made adaptation more practical.
The key idea is simple: you often do not need to move the whole model to change useful behavior. A small learned update can be enough.
## 18. Quantization
**Quantization makes models cheaper to run by reducing numerical precision.**
Instead of representing weights or activations with high-precision numbers, you use lower-precision formats: FP32 to FP16, FP16 to INT8, and sometimes 4-bit.
The benefit is practical: less memory, lower bandwidth, sometimes faster inference, and often cheaper deployment.
But the trade-off is not uniform. Large models can sometimes tolerate aggressive quantization surprisingly well. Smaller models may lose more quality at the same precision. The method, hardware, calibration data, model size, and task all matter.
Quantization does not teach the model new behavior. It changes how the model's numbers are represented.
Not smarter. More deployable.
And in real products, deployable matters.
## 19. Distillation
**Distillation trains a smaller model to imitate a stronger model.**
The larger model is the teacher. The smaller model is the student. The student learns from the teacher's outputs, labels, probability patterns, or generated reasoning traces.
The goal is usually efficiency. A smaller model can be cheaper, faster, easier to deploy, and good enough for a specific use case.
In modern LLM workflows, distillation often also means using a stronger model to generate synthetic training data for a smaller model. Same broad idea: transfer useful behavior from a stronger system into a cheaper one.
But distillation is not a perfect copy. The student can lose breadth, rare capabilities, or edge-case behavior the teacher handled.
The useful question is not: is the student as powerful as the teacher?
The useful question is: is it good enough for this job at this cost?
That is where distillation becomes engineering.
## 20. Inference
Inference is when a trained model is used.
Training updates weights. Inference uses weights. For an LLM, inference means reading the context, computing token probabilities, selecting tokens, and generating output step by step.
This is where product reality appears. Latency matters. Cost matters. Throughput matters. Hardware matters. Context length matters. Caching matters. Batching matters. Tool latency matters.
A model can look amazing in a benchmark or demo and still be too slow, expensive, or unreliable for a real product.
Training creates capability. Inference decides whether that capability can actually be delivered to users.
## 21. Evals
Evals are how you stop judging AI by vibes.
They test whether the model or system behaves the way you expect. A good eval can measure accuracy, format, style, retrieval quality, tool use, grounding, safety, latency, or task success.
The best evals look like real usage: real questions, real edge cases, clear criteria, repeatable scoring. Not cherry-picked demos. Not toy examples.
Evals matter most when something changes: new model, new prompt, new retriever, new chunking strategy, new tool, new guardrail.
Good evals do not prove a system is perfect. They reduce ignorance.
That is already a serious improvement.
## 22. Hallucination
A hallucination is unsupported or incorrect output that sounds plausible.
The "sounds plausible" part is the problem. The model can be fluent, confident, structured, and wrong at the same time.
Hallucinations can appear as fake citations, made-up facts, wrong calculations, invented APIs, incorrect summaries, or misleading interpretations of tool results.
This happens because the model is generating likely text. It is not automatically verifying truth.
You reduce hallucination risk with retrieval, grounding, tools, validation, evals, and human review. But you do not eliminate it completely.
The rule I keep coming back to: fluency is not evidence. Confidence is not correctness.
## 23. Grounding
Grounding connects an answer to evidence.
That evidence can come from documents, databases, web search, tool outputs, logs, citations, or calculations.
Grounding lets you ask: where did this answer come from? Can I verify it? Was the evidence relevant? Did the model use it correctly?
Grounding is broader than RAG. RAG grounds through retrieved text. Tools can ground through live data. Databases can ground through records. Calculators can ground through computation.
But grounding only helps when the evidence is real, relevant, and visible. A citation that does not support the answer is not grounding. It is decoration.
Grounding improves traceability. It does not make the system perfect.
## 24. Guardrails
Guardrails are controls around an AI system.
They can operate on inputs, outputs, tool calls, data access, permissions, schemas, and workflow steps.
A weak guardrail strategy is to add a safety filter at the end. A stronger strategy is layered:
→ what can the user ask?
→ what data can the model see?
→ what tools can it call?
→ what arguments are allowed?
→ what actions need approval?
→ what output is valid?
→ what should be logged?
Guardrails reduce risk. They do not make a system invincible. They also create trade-offs.
Too loose, and the system becomes risky. Too strict, and it becomes frustrating.
Good guardrails are not decoration. They are product design.
## 25. Observability
Observability means seeing what your AI system actually did.
Not just the final answer. The whole run.
What prompt was used? What documents were retrieved? Which chunks were selected? What tool was called? What arguments were passed? What did the tool return? How long did each step take? Where did the system fail? What did the user do next?
This matters because AI failures often hide in the middle. The model may not be the problem. The retriever may have fetched the wrong document. The tool may have returned stale data. The context may have been polluted. The guardrail may have blocked the wrong thing.
Without observability, you debug by vibe. With observability, you debug the system.
Production AI needs traces, not screenshots.
---
The simplest way I now think about modern AI:
The model is only one layer.
> Tokens define what it processes.
> Decoding controls shape how it speaks.
> Context decides what it can use.
> Attention helps it connect information.
> Transformers make scaling practical.
> Embeddings make similarity searchable.
> Retrieval brings in external knowledge.
> RAG combines evidence with generation.
> Prompts guide behavior.
> Context engineering decides what the model sees.
> Tools connect it to software.
> Function calling makes those connections structured.
> Agents turn model calls into loops.
> Fine-tuning and LoRA adapt behavior.
> Quantization and distillation make deployment practical.
> Inference turns capability into a product experience.
> Evals measure quality.
> Grounding ties answers to evidence.
> Guardrails reduce risk.
> Observability shows what actually happened.
AI is no longer just about asking a model better questions. It is about building better systems around the model.
And once you see the system, the vocabulary finally starts to make sense.
Thanks for reading. It's a wrap!!!!