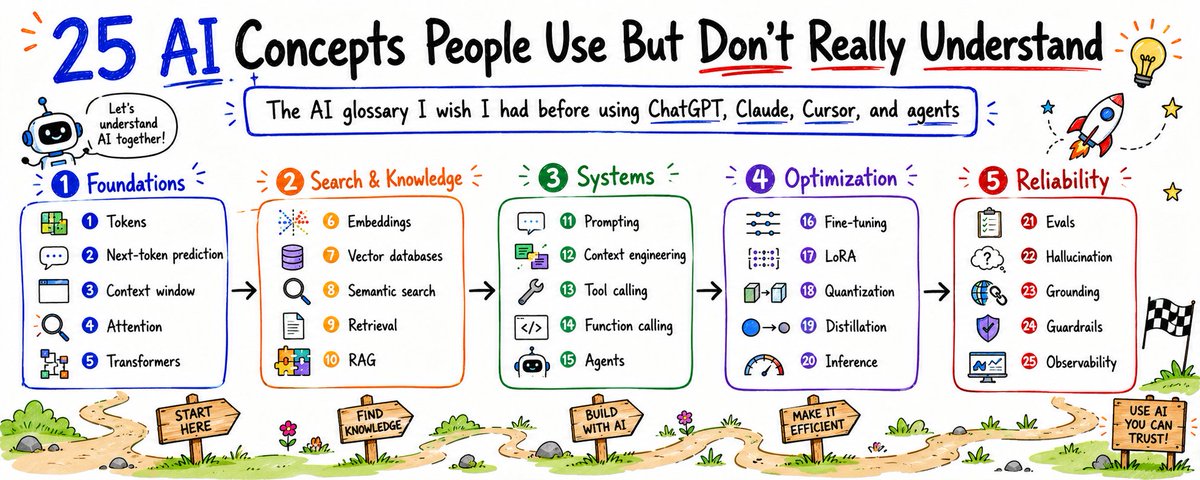
# 25 个常被挂在嘴上、但没几个人真懂的 AI 概念
> **作者**: [@techNmak](https://x.com/techNmak)
> **发布**: 2026-05-25
> **原文**: https://x.com/techNmak/status/2058886981090951627
AI 在大多数人搞清它的词汇之前,就成了主流。
所以你听到的很多 AI 对话,听起来很自信,其实模糊。大家把 "token"、"embedding"、"RAG"、"agent"、"LoRA"、"eval"、"guardrail" 挂在嘴上,仿佛每个人对这些词的理解都一样。
绝大多数时候,并不一样。
这个差距很要紧,因为这些不是花哨的术语。它们是机器的零件。
> 不懂 token,就不懂 context。
> 不懂 embedding,就不懂 semantic search。
> 不懂 RAG,就会高估检索能修的东西。
> 不懂 agent,就会把自主和循环搞混。
> 不懂 eval,就只能凭感觉评判 AI 系统。
所以我想写一份我自己会收藏的指南。
对新手够清晰。对工程师够准确。回头还能再翻。
下面是 25 个让现代 AI 没那么晕的概念。
## 1. Tokens
**关于 LLM,要懂的第一件事:它处理文本的方式,跟我们读文本的方式不一样。** 它处理的是 token。
一个 token 可以是完整的词、词的一部分、标点、空格,或者特殊符号。所以一个词不一定等于一个 token。
**这个小细节几乎决定了一切**——context 长度、成本、延迟、截断、生成。当你发一段 prompt 过去,模型看到的不是"一段话"。它看到的是一串 token ID。
那串 ID 才是模型的原料。所以在搞 context window、定价、生成之前,得先搞懂 token。它们是这个系统里最小的实用单位。
## 2. Next-token prediction(下一个 token 预测)
**说到底,语言模型一直在问同一个问题**——下一个 token 该是什么?
**它读当前的 context,给所有可能的下一个 token 算出一个概率分布。** 选一个 token,加回 context 里,重复这个过程。一段完整的回答就这么出来——不是一次性的,是一个 token 一个 token 长出来的。
这也是为什么同一个 prompt 有时候给出不同答案。模型可能给好几条合理的延续都分了概率。是 decoding 策略决定走哪条。
**Temperature 控制概率分布的尖锐还是平坦。** 低 temperature 让模型更保守。高 temperature 让它更多变,但有时不稳。Top-k 把采样限制在概率最高的 k 个 token 里。Top-p(也叫 nucleus sampling)保留一组 token,让它们的概率累加刚好越过设定的阈值。
这些参数不会改变模型学到的东西。它们只改变模型怎么从已有的可能里做选择。
所以下次你觉得一段答案像"在写作",记住底下发生的事——模型在一步一步把序列长出来。
## 3. Context window
**Context window 是模型一次运行能用的信息。**
它可以装 system prompt、用户消息、对话历史、检索到的文档、工具调用结果、记忆片段、示例、约束。但 context 经常被误解。
**更大的 context window 有用,但不自动等于更好。** 如果你给模型一堆乱、过期、重复或不相关的信息,问题不会消失。你只是把问题搬进了 prompt。
还有质量上的影响:埋在很长 context 中段的信息,被注意到的可靠性比开头或结尾低。
更准的心智模型是:context 是工作记忆。不是存储,不是真理,不是永久知识。只是模型此刻能用的信息。
好的 AI 系统会精挑什么进得了这个空间。它们不会一股脑塞进去,指望模型自己理清楚。
## 4. Attention
Attention 是让现代语言模型在大规模上 work 的关键想法之一。
**简单版:token 可以从其他 token 那里加权吸收信息。** 这让模型能建立对上下文敏感的表示。"Bank" 挨着 "river" 和 "bank" 挨着 "loan" 应该表现不同。Attention 帮模型造出这个差别。
但对现代 decoder-only 的 LLM 来说,有一条重要约束:causal self-attention(因果自注意力)。每个 token 只能 attend 它前面的 token,不能看后面的。这个未来 token mask 保住了 autoregressive 生成。模型不能偷看还没生成的 token。
所以 attention 不是"模型像人一样在理解"。它是一种在可见 context 里路由信息的机制。强大,但仍然只是机制。
## 5. Transformers
**Transformer 是现在大多数文本 LLM 背后的架构。**
最初的突破是把 attention 当成核心操作,不再依赖 recurrence 或 convolution 来做序列建模。一个 transformer block 通常包含 attention、前馈层、残差连接、归一化。把很多这样的 block 叠起来,大规模训练,就有了现代语言模型的骨架。
有一个细节要注意——transformer 在训练和处理 prompt 时可以并行处理输入 token,但生成仍然是 autoregressive 的。模型还是一个 token 一个 token 地输出。
所以 "Transformer" 不是某一个模型,也不是某家公司的产品。它是一族架构,是现代 LLM 能做大规模的原因。
## 6. Embeddings
**Embedding 把数据变成向量。**
文本能变向量。代码能变向量。图像和音频也能。它有用的属性是相似度:如果两段内容相关,它们的向量可能落得很近。
semantic search 就是这么成立的。"how do I make my site faster?" 这样一句查询,能匹配到讲 "page load optimization" 的文档,哪怕字面上完全不重叠。
但 embedding 不是魔法意义。它们是学到的表示。保留某些关系,丢失另一些。
适合产品搜索的 embedding 模型,不一定适合法律文档。适合英文支持文档的,不一定适合代码。
真正要问的不是:我们用没用 embedding?
真正要问的是:这套 embedding 对这个任务有用吗?
## 7. Vector databases(向量数据库)
**向量数据库存 embedding,并能高效地检索附近的向量。**
常见流程很简单:把文档切成 chunk、生成 embedding、连同元数据一起存、把用户查询也 embed、搜附近的向量、返回可能的匹配。
听上去很干净。麻烦的是周围的一切。
文档怎么切的 chunk?元数据保留了吗?过期文档过滤掉了吗?权限尊重了吗?精确字段处理了吗?结果重排了吗?
向量数据库不是大脑。它不知道一份文档真不真。它不知道某条政策昨天改没改。它只是基于向量相似度和你写在外面的过滤逻辑返回候选。
是有用的基础设施。不是完整的 AI 系统。
## 8. Semantic search(语义搜索)
关键词搜索匹配的是词。Semantic search 匹配的是类似"含义"的表示。
所以哪怕用户和文档用词不同,它也能拿到有用结果。这件事很要紧,因为人很少会用你文档里的精确字眼提问。
但 semantic search 不总是比关键词搜索好。有时精确字眼很重要:错误码、API 名、法律条款、版本号、产品 SKU。
这些情况下,纯 semantic search 会漏掉关键词搜索能抓到的东西。
所以很多强检索系统用的是混合搜索。Semantic search 给灵活性。关键词搜索给精度。元数据给约束。重排改善顺序。
搜索不是一招。它是一条 pipeline。
## 9. Retrieval(检索)
检索是指在查询时把外部信息引入系统。
之所以需要它,是因为语言模型有边界。它看不到你的私有数据,除非你给。它不会自动知道训练之后发生了什么。它没法把整个知识库塞进每次请求。
检索是系统在模型回答之前找到相关证据的方式。但检索不只是"搜文档"。它包含切 chunk、建索引、过滤、排序、重排、权限、新鲜度、context 构造。
很多烂答案不是因为模型弱。是因为模型拿到的证据弱:错的 chunk、缺的 chunk、太多的 chunk、过期的 chunk,或者根本没有来源链。
检索的质量经常在模型动笔之前,就把答案的质量定了。
## 10. RAG
RAG 是 Retrieval-Augmented Generation 的缩写。
基本想法很简单:先检索相关信息,再拿这些信息生成答案。这把两件事拆开了。检索器找证据。生成器把证据变成答案。
所以 RAG 对私有文档、新鲜信息、有出处的答案、领域知识都有用。
但 RAG 也是 AI 圈被滥用得最厉害的词之一。它不是简单的"和 PDF 聊天"。它不是 hallucination 的保证修复。它没法让烂文档变可靠。它没法让弱检索变好。
RAG 真正起作用的前提是:对的证据被检索到、被排序、被放进 context、被正确使用。烂检索照样给烂答案。
**RAG 不是真理机器。它是一种设计模式。**
## 11. Prompting
Prompting 是指令层。
它告诉模型你想要什么、它该扮演什么角色、按什么格式、什么约束、模仿什么例子。一个好 prompt 能产生巨大差别。
但 prompt 不是咒语。它不会更新模型权重。它不会补上缺失的知识。它修不好坏掉的检索。它没法让不安全的工具变安全。它替代不了 evaluation。
很多新手就卡在这里。他们一直想用更好的措辞解决系统问题。
有时候问题是 prompt。但很多时候,问题在数据、检索、工具、context、权限或 eval。
Prompting 重要,但它只是一层,不是整个系统。
## 12. Context engineering(上下文工程)
Context engineering 是决定模型该看到什么。
这包括 prompt,也包括检索到的文档、对话历史、工具输出、用户状态、记忆、示例、策略、中间产物。模型只能在它收到的 token 上运转,所以这些 token 的内容、顺序、质量、新鲜度都很要紧。
这就是为什么"用更长的 context window"不够。长 context 给的是容量。Context engineering 给的是相关性。
好系统会问:现在什么有用?什么过期了?什么该总结?什么该检索?什么该藏起来?什么会让模型困惑?
在认真的 AI 系统里,context 是一个工程层面的东西。不是事后补的。
## 13. Tool calling(工具调用)
Tool calling 让模型能和外部系统交互。
模型可以请求计算器、数据库、搜索引擎、code runner、文件查询、日历、CRM、API。但模型通常不直接执行工具。是应用在执行。
模型提议一次 tool call。系统验证它。应用执行它。结果发回给模型。
这个分离很要紧,因为它把权限、数据访问、副作用都留在软件控制下。
一次 tool call 不证明动作发生了。它是一个请求。应用仍然负责验证、授权、执行、重试和错误处理。
模型可以请求。系统必须决定。
## 14. Function calling
**Function calling 是结构化的 tool calling。**
模型不再返回一段松散文本,而是返回符合某个 schema 的参数。比如:function get_weather, location Mumbai, unit celsius。
这种结构让软件更容易解析、验证、路由、测试和拒绝。这就是 function calling 在生产系统里的价值。
自由文本是灵活的。结构化输出是可控的。
但同一条规则仍然适用:function call 不代表函数已经跑过了。它是一个结构化请求。应用仍然要决定要不要执行、怎么执行。
Schema 在前。执行在后。这是生产心智。
## 15. Agents
"Agent" 是 AI 里被拉得最长的词之一。
我自己实用的理解:agent 是一个能循环的系统。它能 plan、调用工具、观察结果、更新状态、决定下一步。
这个循环就是它和单次 prompt-response 的差别。但自主性是个光谱。很多有用的 agent 并不完全自主。它们是有边界的系统:工具有限、目标窄、停止条件清晰、有风险动作时需要人审批。
这往往才是更好的。
而且,agent 不会自动跨 session 记住一切。持久记忆得显式设计:存什么、什么时候检索、怎么更新、什么时候忽略。
好 agent 强大不是因为它能做任何事。它有用是因为它能在正确的边界里做正确的事。
难的不是给模型工具。难的是控制这些工具怎么被使用。
## 16. Fine-tuning
Fine-tuning 改变模型。Prompting 改变输入。
这一个区分能澄清很多事。
Fine-tuning 从一个预训练模型出发,继续在更窄的任务或领域示例上训练它。它对重复出现的 pattern 有用:tone、术语、分类、格式、领域行为或任务执行。
但 fine-tuning 不是所有 AI 问题的答案。如果模型缺新鲜知识,检索可能更好。如果问题是输出结构,prompting 或 function calling 可能就够。如果问题是安全,你需要 guardrail 和 eval。
很多人把 fine-tuning 和 alignment 混淆,也是在这里。**搭一个 assistant 的常见流水线是:**
pretraining → supervised fine-tuning → reward modeling → RL optimization
预训练给模型宽广的能力。Supervised fine-tuning 用精选样本教它跟随指令。RLHF 再用人类偏好反馈精修行为。RLAIF 是一个相关思路,让 AI 反馈替代或补充人类反馈。
所以有用的心智模型是:fine-tuning 调整行为,instruction tuning 教响应格式和合规,RLHF/RLAIF 精修对齐。它们相关,但不是同一回事。
## 17. LoRA
LoRA 是 Low-Rank Adaptation 的缩写。
它是一种参数高效的大模型适配方法。LoRA 不更新所有模型权重,而是冻结基础模型,只在选定层里训练小的低秩矩阵。
这把可训练参数的数量大幅降下来。更少内存、更少算力、更快实验。
基础模型基本保持原样。Adapter 承载任务专属的变化。这就是 LoRA 在开源模型工作流里这么火的原因。它让"适配"变实用了。
核心想法很简单:你常常不需要把整个模型搬走,才能改变有用的行为。一个学到的小更新就够。
## 18. Quantization(量化)
**量化通过降低数值精度,让模型跑起来更便宜。**
不再用高精度的数表示权重或激活,而是用更低精度的格式:FP32 到 FP16、FP16 到 INT8,有时到 4-bit。
好处很实在:内存更小、带宽更低、有时推理更快、部署更便宜。
但代价不是均匀的。大模型有时能在很激进的量化下表现得意外地好。小模型在同样精度下可能丢失更多质量。方法、硬件、校准数据、模型大小、任务都要紧。
量化不教模型新行为。它改的是模型的数字怎么被表示。
不是更聪明。是更好部署。
而在真实产品里,"好部署"这件事本身就要紧。
## 19. Distillation(蒸馏)
**蒸馏训练一个小模型去模仿一个更强的模型。**
大模型是 teacher。小模型是 student。Student 从 teacher 的输出、标签、概率分布或生成的推理轨迹里学。
目标通常是效率。一个小模型可以更便宜、更快、更容易部署、对某个具体用例足够好。
在现代 LLM 工作流里,蒸馏经常也意味着用一个更强的模型生成合成训练数据,再用来训小模型。同样的大思路:把有用行为从更强的系统迁到更便宜的系统。
但蒸馏不是完美复制。Student 可能丢掉广度、罕见能力,或者 teacher 处理得了的边界情况。
有用的问题不是:student 跟 teacher 一样强吗?
有用的问题是:在这个成本下,它对这件事够用吗?
蒸馏在这个问题上变成工程。
## 20. Inference(推理)
Inference 是训练好的模型被使用的过程。
训练更新权重。Inference 使用权重。对一个 LLM 来说,inference 就是读 context、算 token 概率、选 token、一步一步生成输出。
这是产品现实出现的地方。延迟要紧。成本要紧。吞吐要紧。硬件要紧。Context 长度要紧。Caching 要紧。Batching 要紧。工具延迟要紧。
一个模型可能在 benchmark 或 demo 上看着惊艳,仍然太慢、太贵、太不稳,没法上真实产品。
训练造出能力。Inference 决定那种能力能不能真的交付到用户手里。
## 21. Evals(评估)
Eval 是你停止凭感觉判断 AI 的方式。
它们测试模型或系统的行为是不是符合预期。一个好 eval 可以衡量准确度、格式、风格、检索质量、工具使用、grounding、安全、延迟或任务成功率。
最好的 eval 看起来像真实使用:真实问题、真实边界情况、清晰的标准、可重复的打分。不是精挑的 demo。不是玩具示例。
Eval 在有变更时最要紧:新模型、新 prompt、新检索器、新切分策略、新工具、新 guardrail。
好 eval 不证明系统完美。它减少无知。
这本身就是很认真的进步。
## 22. Hallucination(幻觉)
Hallucination 是听起来合理、但没有支撑或不正确的输出。
"听起来合理"才是问题。模型可以同时是流畅的、自信的、结构化的,并且是错的。
Hallucination 可以表现为:假引用、瞎编的事实、错误的计算、虚构的 API、错误的总结,或者对工具结果的误读。
这件事会发生,是因为模型在生成"可能的文本"。它不会自动验证真伪。
你用检索、grounding、工具、validation、eval 和人工审查降低 hallucination 风险。但你没法完全消除。
我反复回到的一条规则:"fluency is not evidence. Confidence is not correctness."(流畅不是证据,自信不是正确)
## 23. Grounding(接地)
Grounding 把答案和证据连起来。
证据可以来自文档、数据库、网页搜索、工具输出、日志、引用或计算。
Grounding 让你能问:这个答案是哪来的?我能验证吗?证据相关吗?模型用对了吗?
Grounding 比 RAG 更宽。RAG 通过检索到的文本 ground。工具能通过实时数据 ground。数据库能通过记录 ground。计算器能通过计算 ground。
但 grounding 只在证据真实、相关、可见的时候有用。一个不支撑答案的引用不是 grounding。是装饰。
Grounding 改善可追溯性。它不会让系统变完美。
## 24. Guardrails
Guardrail 是 AI 系统周围的控制。
它们可以作用在输入、输出、tool call、数据访问、权限、schema 和工作流步骤上。
弱的 guardrail 策略是在最后加一个安全过滤器。强的策略是分层的:
→ 用户能问什么?
→ 模型能看到什么数据?
→ 它能调哪些工具?
→ 允许什么参数?
→ 哪些动作要审批?
→ 什么输出算合法?
→ 什么需要被记录?
Guardrail 降低风险。它们不会让系统刀枪不入。它们也带来权衡。
太松,系统就有风险。太紧,系统就让人窝火。
好 guardrail 不是装饰。它是产品设计。
## 25. Observability(可观测性)
Observability 意味着看见你的 AI 系统真正做了什么。
不只是最终答案。整次运行的全过程。
用了什么 prompt?检索到了哪些文档?哪些 chunk 被选了?调用了哪个工具?传了什么参数?工具返回了什么?每一步耗时多少?系统在哪里失败了?用户接下来做了什么?
这件事要紧,是因为 AI 失败常常藏在中间。模型可能不是问题。检索器可能取错了文档。工具可能返回了过期数据。Context 可能被污染了。Guardrail 可能挡错了东西。
没有 observability,你只能凭感觉调试。有 observability,你才能调试系统。
生产 AI 需要的是 trace,不是截图。
---
我现在对现代 AI 最简单的理解:
模型只是其中一层。
> Token 定义它处理的是什么。
> Decoding 控制它说话的形态。
> Context 决定它能用什么。
> Attention 帮它在信息之间建立连接。
> Transformer 让 scaling 变实用。
> Embedding 让相似度可搜索。
> Retrieval 把外部知识带进来。
> RAG 把证据和生成结合起来。
> Prompt 引导行为。
> Context engineering 决定模型看到什么。
> 工具把它和软件连起来。
> Function calling 让那些连接结构化。
> Agent 把模型调用变成循环。
> Fine-tuning 和 LoRA 调整行为。
> Quantization 和 distillation 让部署变实用。
> Inference 把能力变成产品体验。
> Eval 衡量质量。
> Grounding 把答案绑到证据上。
> Guardrail 降低风险。
> Observability 让你看见真正发生了什么。
AI 不再只是关于"怎么向模型问更好的问题"。它关乎在模型周围搭建更好的系统。
而一旦你看见了这个系统,那套词汇才真正讲得通。
感谢阅读。结束撒花!!!!