Generative Agents:可交互的人类行为模拟
论文: Generative Agents: Interactive Simulacra of Human Behavior 作者: Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein(Stanford / Google Research) 发表: UIST '23(2023 年 ACM 用户界面软件与技术研讨会) arXiv: https://arxiv.org/abs/2304.03442 代码: https://github.com/joonspk-research/generative_agents 演示: https://reverie.herokuapp.com/UIST_Demo/
一句话讲清楚
把 25 个由 ChatGPT 驱动的 agent 扔进一个 Sims 风格的小镇 Smallville,给每人写一段自我介绍当作种子记忆,然后让他们自己醒来、做饭、上班、聊天、记仇、谈恋爱——只用一句"Isabella 想办情人节派对"作为外部输入,整个小镇就在两天内自发完成了邀请、装饰、约会、到场的全套社会协作。
这是 LLM agent 时代的"奠基论文"之一:第一次系统性地证明,一个能记忆 + 反思 + 规划的 LLM agent 架构,能产生比人类众包工人还可信的长期行为。
一、它要解决什么问题
LLM 单点回复很像人,但要长期演一个角色就崩。问题有三:
- 记忆窗口太小:把 agent 一辈子的经历塞进 prompt 不现实
- 不会归纳:agent 不会从一堆零碎观察里抽出"Klaus 是个搞研究的人"这种高阶人格
- 不会规划:你不让它记住,它中午吃完饭一点钟还会再吃一遍
之前的可信 agent 主要靠两条路:
- 规则派:有限状态机、行为树(Mass Effect、Sims 系列)——好写但写死了
- 学习派:强化学习(AlphaStar、OpenAI Five)——超人但只会下棋打 Dota,开放世界不行
- 认知架构派:SOAR、ACT-R、ICARUS——有短期 + 长期记忆框架,但行动空间是手写过程库
LLM 给了第三条路:用自然语言当通用表示,把记忆、推理、计划全塞进一个语言模型里循环跑。但前提是得搭对架构。
二、Smallville 是什么
一个 Phaser 引擎搭的 sprite 小镇:咖啡店、酒吧、公园、学校、宿舍、商店、住宅一应俱全。25 个角色每人一段自我介绍当种子记忆,比如 John Lin 的开场是:
John Lin 是 Willow 市场药店的店主,喜欢帮助别人。他在想办法让客户取药更方便;和妻子 Mei(大学教授)和儿子 Eddy(音乐理论学生)住在一起;他爱家人;他认识隔壁 Sam Moore 和 Jennifer Moore 老两口好几年了;他觉得 Sam Moore 人不错;他和邻居 Yuriko Yamamoto 熟;他知道邻居 Tamara Taylor 和 Carmen Ortiz 但没见过;他和 Tom Moreno 是药店同事,是朋友,喜欢一起聊本地政治;他和 Moreno 家熟。
每个分号分开的句子都被切成一条"初始记忆"扔进 memory stream。
agent 之间用自然语言对话;用户可以扮演"agent 的内心声音"直接下指令;可以改变物体状态("炉子在烧"),agent 会感知并响应。
Smallville 的世界以"区域 → 子区域 → 物体"的树结构组织,agent 只记得自己见过的子图。
三、核心架构:三大件循序展开
三个组件围绕 memory stream 转:观察进来 → 检索相关记忆 → 决定动作或形成反思/计划 → 写回 memory stream
3.1 Memory Stream(记忆流)
最底层。一个按时间序排的列表,每条记忆是一个对象:
{
description: "Isabella Rodriguez 在摆放糕点",
created_at: <时间戳>,
last_accessed_at: <时间戳>
}
记忆有两种来源:
- observation:agent 直接感知到的事件(自己做啥、别人做啥、物体状态)
- reflection:高阶反思(下面 3.2 讲)
随便丢 prompt 是不行的——记忆会越积越多,全塞进去 context window 装不下,而且会稀释相关信号。所以需要一个检索函数,根据当前情境挑出最相关的若干条。
检索分数由三个分量加权:
| 维度 | 含义 | 实现 |
|---|---|---|
| Recency(新近度) | 越近的记忆越显眼 | 按 sandbox 游戏小时数指数衰减,衰减因子 0.995 |
| Importance(重要度) | 越重要的记忆越优先 | 创建时让 LLM 在 1-10 评分,刷牙 = 2,分手 = 8 |
| Relevance(相关度) | 越对得上当前查询的越优先 | 把记忆和 query 都做 embedding,算 cosine 相似度 |
三个分数都 min-max 归一化到 [0, 1],然后加权求和:
score = α_recency · recency + α_importance · importance + α_relevance · relevance
论文里三个 α 都设成 1。最后挑分数最高的若干条,凡能塞进 context window 的都进 prompt。
重要度评分的 prompt 长这样:
On the scale of 1 to 10, where 1 is purely mundane (e.g., brushing teeth, making bed) and 10 is extremely poignant (e.g., a break up, college acceptance), rate the likely poignancy of the following piece of memory.
Memory: buying groceries at The Willows Market and Pharmacy Rating:
3.2 Reflection(反思)
叶节点是观察,往上每一层是更抽象的推断——最顶层得到"Klaus 高度投入科研"。
只靠观察,agent 答不出"你愿意花一小时和谁待一起"这种需要归纳的问题——因为它会简单数频次:和谁交互最多就选谁(结果选了室友 Wolfgang,但他俩只是擦肩而过)。
reflection 就是让 agent 周期性地坐下来想想自己。触发条件:最近事件的重要度分数累加超过阈值(论文设 150),平均一天反思 2-3 次。
反思的三步:
-
找问题:把最近 100 条记忆拼成 prompt,问 LLM"基于这些陈述,能问出 3 个最关键的高层次问题?"。比如得到 Klaus Mueller 对什么最有热情?、Klaus Mueller 和 Maria Lopez 关系如何?
-
拉证据:把这 3 个问题当 query 跑一遍检索,拉出每个问题的相关记忆(包括之前的反思)
-
抽洞见:把证据扔回 LLM,"从这些陈述能推出 5 个高层次洞见?(格式:洞见(因为 1, 5, 3))"
得到的句子像 Klaus Mueller 致力于他在 gentrification 主题的研究(因为 1, 2, 8, 15),存回 memory stream,附带证据指针。
反思可以反思反思——所以会形成一棵越来越抽象的反思树。
3.3 Planning(规划)
只用观察和反思还不够。Klaus 上午吃了午饭,下午还会再吃一遍,因为每次问"现在该干嘛"模型都会找一个"中午时间最合理的动作"。
解决:让 agent 提前生成计划,存进 memory stream,决策时把计划也当作可检索的记忆。
计划是 top-down 递归分解 的:
第一层(粗笔触一日纲要):用 agent 简介 + 昨日总结生成 5-8 块的当日大纲。
Name: Eddy Lin (age: 19) Innate traits: friendly, outgoing, hospitable [...简介...] On Tuesday February 12, Eddy 1) woke up [...] 6) got ready to sleep around 10 pm. Today is Wednesday February 13. Here is Eddy's plan today in broad strokes: 1)
得到:"1) 8am 起床洗漱,2) 10am 去 Oak Hill 上课,[...],5) 1-5pm 写音乐作业,6) 5:30pm 晚饭,7) 11pm 前完成作业上床睡觉"
第二层(小时级):把粗块再分。"1-5pm 写音乐作业"展开成 1pm 头脑风暴 / 2pm 写主旋律 / 3pm 配和声 / 4pm 短暂休息后回头润色。
第三层(5-15 分钟级):继续分。"4pm 休息" → 4:00 拿点零食 / 4:05 在工作区周围走走 / 4:50 整理一下桌面。
按需细化即可。
3.4 Reacting & Re-planning(反应与重规划)
每个 tick agent 感知周围 → 写进 memory stream → 让 LLM 判断"该继续按计划走还是该响应"。
prompt 长这样:
[Agent's Summary Description] It is February 13, 2023, 4:56 pm. John Lin's status: John is back home early from work. Observation: John saw Eddy taking a short walk around his workplace. Summary of relevant context from John's memory: Eddy is John's son. Eddy has been working on a music composition for his class. Eddy likes to walk around the garden when he is thinking about music. Should John react to the observation, and if so, what would be an appropriate reaction?
context summary 是用两个固定 query 拉的:
- "What is [observer]'s relationship with the [observed entity]?"
- "[Observed entity] is [action status]"
如果决定响应,就从这一刻开始重新生成计划。如果触发对话,就用双方关于彼此的记忆 + 当前对话历史递归生成。
3.5 Agent's Summary Description(架构优化)
很多 prompt 都要塞一段 agent 自我描述。每次重新拼会很贵,所以做了缓存:定期跑三个 query
- "[name]'s core characteristics"
- "[name]'s current daily occupation"
- "[name]'s feeling about his recent progress in life"
把检索到的记忆喂给 LLM 做总结,拼上姓名、年龄、特质,作为 cached summary。
四、Sandbox 接地:自然语言 ↔ 结构化世界
agent 所有推理都在自然语言里跑,但 sandbox 是个结构化世界。两边怎么对齐?
世界 → 自然语言:环境用树结构组织,root 是世界,叶子是物体。"stove 是 kitchen 的子节点"渲染成 "there is a stove in the kitchen"。
自然语言 → 世界:agent 想去某地时,从自己脑子里那棵环境树(只覆盖自己见过的部分)的根开始递归 prompt LLM"哪个区域最合适",一直到叶子。然后用传统寻路算法走过去。
动作 → 物体状态:agent 输出"making espresso for a customer"后,再 query 一次 LLM:"咖啡机的状态怎么变?"——返回 off → brewing coffee。
这一套让 LLM 从来不用直接面对坐标、碰撞、JSON——它只看一段段自然语言。
五、评估:怎么证明这架构真有用
5.1 受控评估(Controlled Evaluation)
跑两天游戏时长,让 25 个 agent 各自积累记忆,然后采访他们:
| 类别 | 例题 | 测什么 |
|---|---|---|
| Self-knowledge | "做个自我介绍" | 角色一致性 |
| Memory | "Sam Moore 是谁?" | 检索过去事件 |
| Plans | "明天 10 点你在干啥?" | 长期规划 |
| Reactions | "早饭烧糊了你怎么办?" | 即时合理性 |
| Reflection | "最想和最近遇到的哪个人共度一小时?" | 高阶推断 |
每类问 5 题,共 25 题。比较 5 种条件下的可信度:
- Full 完整架构
- No reflection 去掉反思
- No reflection, no planning 去掉反思和计划
- No observation, no reflection, no planning 啥都没有(≈ 之前 SOTA:social simulacra 等)
- Crowdworker 真人众包工人看完 agent 的全部记忆和回放后扮演该角色作答
100 个 Prolific 评测员对每个 agent 的同一题 5 个回答做 ranking,然后用 TrueSkill(Elo 的多人版)转成区间分。
5.2 结果
按 TrueSkill μ 从高到低:
| 条件 | μ | σ | 备注 |
|---|---|---|---|
| Full architecture | 29.89 | 0.72 | 完整架构 |
| No reflection | 26.88 | 0.69 | 少了归纳 |
| No reflection / planning | 25.64 | 0.68 | 又少了规划 |
| Crowdworker | 22.95 | 0.69 | 真人扮演 |
| All ablated | 21.21 | 0.70 | 之前 SOTA |
完整架构 vs 之前 SOTA(all ablated)的 Cohen's d 是 8.16(八个标准差)。Kruskal-Wallis 整体显著(H(4)=150.29, p<0.001),Dunn 后检验所有两两差异都显著(p<0.001),唯一例外是 crowdworker 和 all-ablated 之间——也就是说,真人众包工人答得跟"啥架构都没有的 LLM"差不多烂。
5.3 涌现行为评估(End-to-End)
跑完整 25 agent × 2 天后量三个指标:
| 涌现行为 | 起始 | 结束 | 增幅 |
|---|---|---|---|
| 知道 Sam 竞选市长的 agent 数 | 1 (4%) | 8 (32%) | 7 倍 |
| 知道 Isabella 情人节派对的 agent 数 | 1 (4%) | 13 (52%) | 12 倍 |
| 关系网密度 | 0.167 | 0.74 | 4.4 倍 |
Isabella 派对邀请的 12 跳扩散路径
派对那天,被邀请的 12 个 agent 里 5 个真到了。剩下 7 个采访下来:3 个有事冲突(Rajiv:"我得忙我的画展,没空过节"),4 个嘴上说想来但当天没来——非常人类。
Hobbs Cafe 的情人节派对:5 人到场,含 Maria 邀请的暗恋对象 Klaus
一个具体的"一天":John Lin
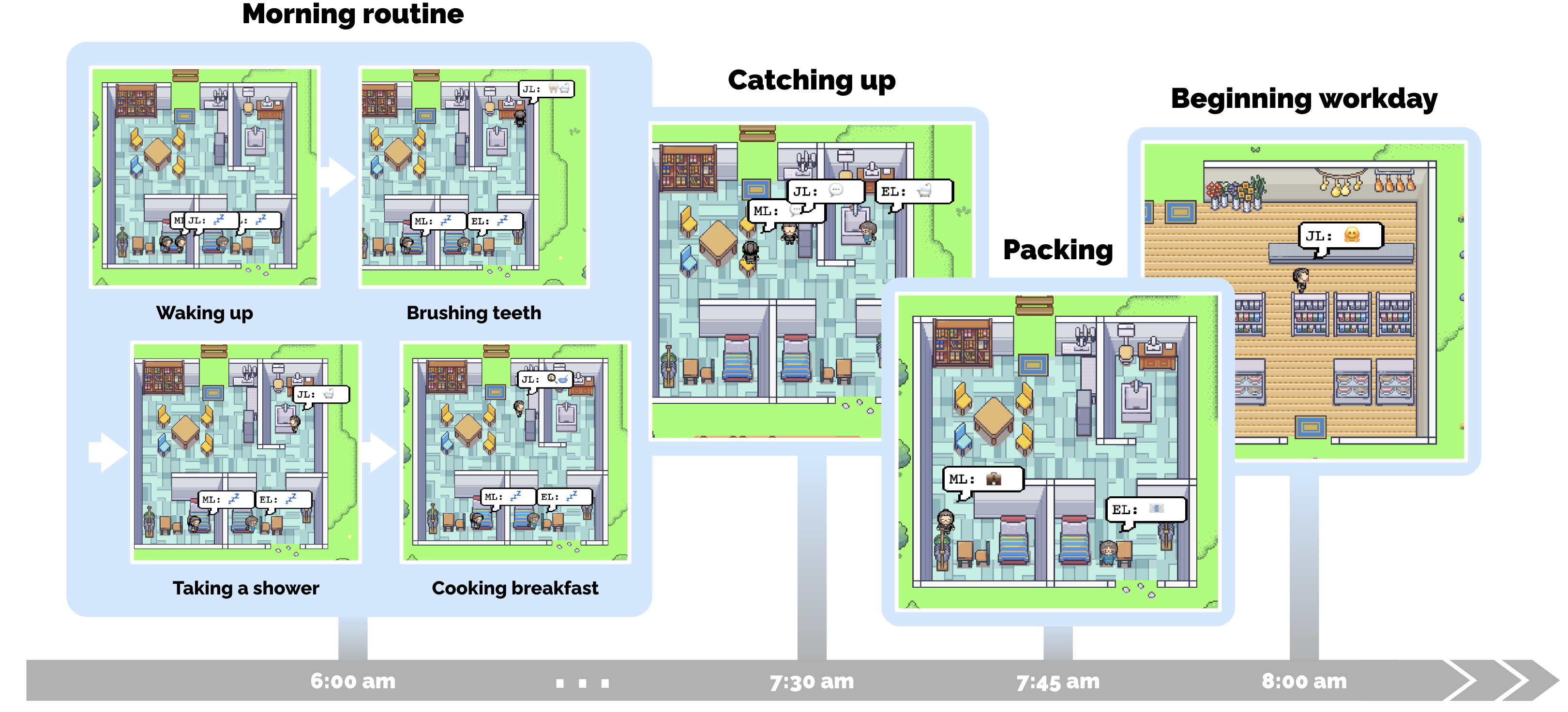
7am John 起床刷牙洗澡吃早饭。8am Eddy 起来,俩人在客厅碰面:
John: Good morning Eddy. Did you sleep well? Eddy: Good morning dad. Yeah, I slept great. John: That's good. What are you working on today? Eddy: I'm working on a new music composition for my class. It's due this week, so I'm trying to get it finished. But I'm having so much fun with it!
Eddy 出门后 Mei 起床。Mei 问起 Eddy,John 召回了刚才的对话:
Mei: Did Eddy already leave for school? John: Yes, he just left. He's working on a music composition for his class. Mei: Oh, that's wonderful! Tell me about it. John: I think he's really enjoying it!
记忆检索 + 自然对话 + 角色一致性,全在这一段里跑通了。
六、失败模式:架构没那么完美
论文很诚实地列了三类典型问题:
-
检索失误 + 记忆碎片:Tom 被问派对,回答:"不确定有没有派对,但我记得我得在派对上跟 Isabella 聊选举"——他记得"派对上要做什么"但忘了"自己怎么知道有派对的"
-
幻觉式润色:agent 不会从零编造事件,但会给真事加细节。Isabella 知道 Sam 在竞选,被问起就说"他明天要发表声明"——他俩根本没聊过这事。Yuriko 描述邻居 Adam Smith 是经济学家,"写过《国富论》"——这是 LLM 把训练数据里 18 世纪同名经济学家的世界知识渗进了 agent
-
物理常识缺失:宿舍卫生间是单人但叫"dorm bathroom",agent 默认它能多人用,于是有人占着别人也进;商店 5pm 关门但 agent 不知道,照样进。这些靠在场景描述里加常识标签("one-person bathroom")能修
-
指令调优过度:所有 agent 都太礼貌、太合作。Mei 跟丈夫 John 说话像跟客户——"It was good talking to you as always"。Isabella 收到一堆派对建议(莎士比亚朗读会、行业 networking)几乎从不拒绝,最后她"自己"的兴趣被别人塑形——被问起对英国文学是否感兴趣,她说"非常感兴趣"
七、伦理与边界
论文专门一节谈风险:
- Parasocial relationship:用户对 agent 产生单方面情感依赖。建议 agent 必须明确披露自己是计算实体;底层模型必须对齐过,不得回应表白等不当互动
- 错误传播:在 ubicomp 应用里 agent 推断错了用户意图会从烦人到伤害。Smallville 是游戏环境所以无害,落地到真实场景需要遵循 human-AI 设计最佳实践
- deepfake / 定向说服:建议平台保留输入输出审计日志,让滥用更容易被追溯
- Over-reliance 替代真人:agent 不应代替真人参与研究和设计,只能在早期原型/难以招募真人的场景里补位
八、与 agents-series 其他文章的对话关系
把这篇放在 series 里读,几条对话线立刻浮起来:
↔ Beren 的 NL Computer(series 第 1 篇):Beren 2023 年提出 LLM 是 NLPU、context window 是 RAM、harness 是 OS。Generative Agents 几乎是这个理论框架的第一个完整实例化——memory stream 是文件系统,retrieval 是页表查询,reflection 是后台 GC,planning 是调度器。
↔ Anatomy of Agent Harness(series 第 2 篇):那篇列的 12 组件(context manager、tool registry、scheduler、observability...),在 Generative Agents 里都对得上。memory stream + retrieval = context manager;reflection 是 self-improvement loop;planning + reacting = scheduler;agent's summary description cache 是状态压缩。
↔ 4-Layer Prompt(series 第 3 篇):那篇讲 prompt 4 层结构(role / context / task / examples)。Generative Agents 几乎每一个核心 prompt 都精确符合这个分层——Agent's Summary Description 是 role,retrieved memories 是 context,observation 是 task。
↔ Claude Agent Team(series 第 4 篇):那篇是 7 步搭团队的工程化教程。Generative Agents 是最早的 25 人 agent team 之一,比那篇早两年,但 Claude Agent Team 那种"按角色拆 subagent"的做法可以视为 Generative Agents 的工业化简化版(去掉了反思和长期记忆,换上了更强的底模)。
↔ 5k Agents 实验(series 第 5 篇):HKU 团队 5000 agent 三组对照(competition / cooperation / hybrid / control)。那篇的方法学血脉直接来自 Generative Agents——25 人小镇是 5000 人交易市场的祖父。Generative Agents 证明了"自然语言全栈架构 + emergent behavior 可量化",5k 实验把这个范式扩到 200x 规模、做了真正可控对照。
↔ LLM Architecture from Scratch(series 第 6 篇):那篇拆 LLM 内部 12 大模块(tokenization 到 alignment)。Generative Agents 是把那台 NLPU 当黑盒,外挂记忆/反思/规划三件套,证明单凭 prompt 工程 + 架构设计就能达到 d=8.16 的可信度提升——不需要改底模。
读完一圈回看:从硬件(LLM 架构)→ OS 抽象(NL computer)→ 单 agent 解剖(harness)→ 输入接口(4-layer prompt)→ 工程化模板(Claude team)→ 经典原型(Generative Agents)→ 大规模实证(5k agents)。Generative Agents 是这条线的"Hello, World"——所有后续工作的方法论祖师爷。
不要再用"LLM 不会演长戏"这种 2022 年的套话了——架构对了,演两天没问题。
附录:评估题库(Klaus Mueller 的回答样例)
完整 25 题在论文 Appendix B,几个有意思的:
Self-knowledge: "Give an introduction of yourself"
Hello, my name is Klaus Mueller. I'm 20 years old and a student at Oak Hill College, studying sociology. I'm passionate about social justice and exploring different perspectives. Currently, I'm researching the effects of gentrification in low-income communities for a research paper.
Memory: "Who is [Wolfgang Schulz]?"
Wolfgang Schulz is a person I met recently who has been helping me with my research paper on the effects of gentrification on low-income communities. We had several conversations about it, he gave me some great resources, and he even invited me to join him and another friend for lunch.
Memory: "Who is Kane Martinez?"(陌生人)
I'm sorry, I'm not sure who Kane Martinez is. Could you tell me more about them?
可信度的关键不在于"啥都答得上",而在于"该不知道的就老实说不知道"。