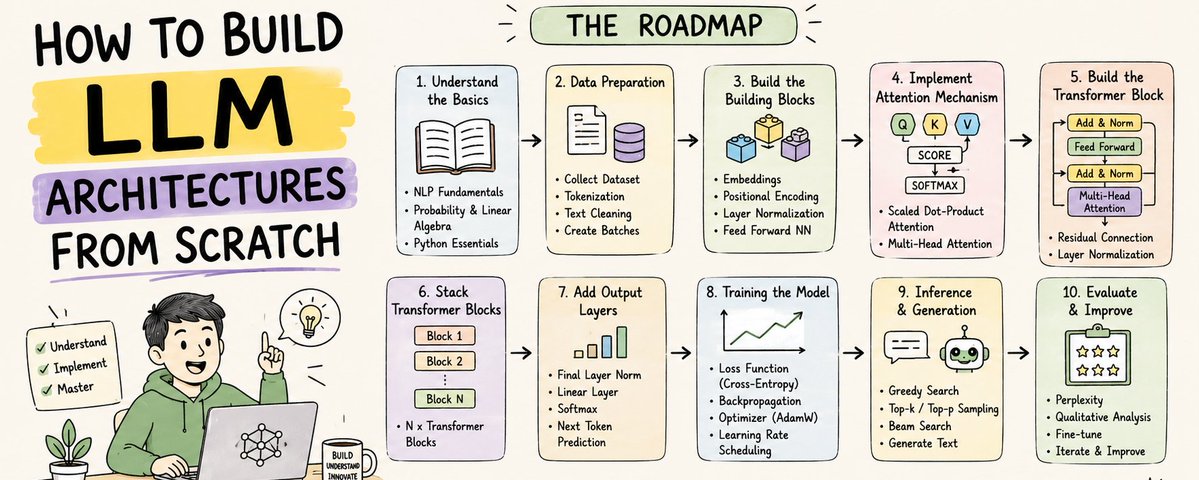
# How to Build LLM Architectures From Scratch
> **Source**: [@shabnam_774 on X](https://x.com/shabnam_774/status/2058517919760355729) · 2026-05-24
>
> A Deep Dive Into the Systems Behind Models Like OpenAI ChatGPT and Anthropic Claude
---
Most people use AI models every day.
Very few understand how they're actually built.
Under the hood, Large Language Models (LLMs) are not magic.
They are massive prediction systems trained on huge amounts of text using carefully designed neural network architectures.
But building one from scratch is far more complex than simply "training a chatbot."
It involves:
- Data engineering
- Tokenization
- Transformer architectures
- Distributed training
- GPU optimization
- Reinforcement learning
- Inference systems
- Alignment layers
- Memory optimization
This article breaks down the full architecture of modern LLMs step-by-step in a practical and understandable way.
---
# 1. What Is an LLM?
A Large Language Model is a neural network trained to predict the next token in a sequence.
Example:
Input:
> "The future of AI is"
The model predicts:
> "transformative"
Then continues predicting one token at a time.
That's the foundation of systems like:
- OpenAI GPT models
- Anthropic Claude
- Google Gemini
- Meta Llama
At scale, this simple prediction process becomes incredibly powerful.
---
# 2. The Core Pipeline of Building an LLM
The full process looks like this:
```
Raw Internet Data
↓
Cleaning + Filtering
↓
Tokenization
↓
Transformer Architecture
↓
Pretraining
↓
Fine-Tuning
↓
RLHF / Alignment
↓
Inference Optimization
↓
Deployment
```
Every stage matters.
A weak dataset or poor architecture design can ruin the entire model.
---
# 3. Step One: Data Collection
LLMs need enormous datasets.
Modern frontier models train on:
- Books
- Wikipedia
- Research papers
- Websites
- Code repositories
- Documentation
- Conversations
- Forums
Data sources may include:
- Common Crawl
- GitHub
- ArXiv
- Stack Overflow
- Public datasets
The goal is diversity + scale.
A small model trained on excellent data often beats a larger model trained on noisy data.
---
# 4. Data Cleaning and Filtering
Raw internet data is messy.
You must remove:
- Spam
- Duplicates
- Low-quality text
- Toxic content
- Broken formatting
- Repeated sequences
- AI-generated garbage
This stage is massively underestimated.
Companies spend enormous resources on data quality because:
> Better data > Bigger models
Common filtering methods include:
- Deduplication
- Heuristic filtering
- Quality scoring
- Language detection
- Safety filtering
- NSFW removal
---
# 5. Tokenization: Converting Text Into Numbers
Neural networks don't understand words.
They understand numbers.
So text becomes tokens.
Example:
```
"ChatGPT is powerful"
↓
[1532, 4021, 318, 7821]
```
This process is called tokenization.
Popular tokenization methods:
- BPE (Byte Pair Encoding)
- SentencePiece
- WordPiece
Tokens can represent:
- Words
- Subwords
- Characters
- Punctuation
Efficient tokenization dramatically affects performance and cost.
---
# 6. Embeddings: Giving Tokens Meaning
Tokens are converted into vectors.
A vector is basically a list of numbers representing semantic meaning.
Example:
```
King → [0.2, -0.8, 1.4, ...]
Queen → [0.3, -0.7, 1.5, ...]
```
Similar concepts end up close together in vector space.
This is how models learn relationships between words.
Embeddings are the foundation of semantic understanding.
---
# 7. The Transformer Architecture
This changed everything.
The Transformer architecture was introduced in the landmark paper:
> "Attention Is All You Need" by Google Brain researchers in 2017.
Transformers replaced older systems like:
- RNNs
- LSTMs
Because they scaled dramatically better.
The Transformer architecture powers nearly every modern LLM today.
---
# 8. Self-Attention: The Heart of LLMs
Self-attention allows the model to determine:
> Which words matter most in context.
Example:
"The animal didn't cross the street because it was tired."
The model learns that:
> "it" refers to "animal"
not "street."
Self-attention dynamically weighs relationships between tokens.
This enables contextual understanding.
---
# 9. Understanding Q, K, and V (Query, Key, Value)
Attention works using:
- Query vectors
- Key vectors
- Value vectors
Think of it like search.
Each token asks:
> "Which other tokens are relevant to me?"
Then attention scores determine importance.
Formula:
```
Attention(Q,K,V) = softmax(QKᵀ / √dₖ)V
```
This is one of the most important equations in modern AI.
---
# 10. Multi-Head Attention
Instead of using one attention mechanism:
LLMs use many attention heads simultaneously.
Each head learns different relationships:
- Grammar
- Logic
- Syntax
- Context
- Long-term dependencies
This massively improves representation learning.
---
# 11. Positional Encoding
Transformers process tokens in parallel.
But language has order.
So models need positional information.
Example:
```
Dog bites man
Man bites dog
```
Same words. Completely different meaning.
Positional encoding helps the model understand sequence structure.
---
# 12. Feed Forward Networks
After attention layers, tokens pass through feed-forward neural networks.
These layers:
- Refine representations
- Increase nonlinearity
- Improve reasoning capacity
A transformer block usually contains:
```
Attention
↓
Normalization
↓
Feed Forward Network
↓
Normalization
```
Repeated dozens or hundreds of times.
---
# 13. Scaling Laws
One major discovery in AI:
> Bigger models trained on more data generally perform better.
Scaling involves:
- More parameters
- More tokens
- More compute
Examples:
- GPT-2 → 1.5B parameters
- GPT-3 → 175B parameters
Modern frontier systems may use trillions of parameters (sometimes via Mixture-of-Experts).
---
# 14. Training the Model
Training means adjusting weights to minimize prediction error.
Process:
```
Input sentence
↓
Predict next token
↓
Compare prediction vs actual token
↓
Calculate loss
↓
Backpropagation
↓
Update weights
```
This repeats billions of times.
Training large models can require:
- Thousands of GPUs
- Weeks or months
- Massive distributed systems
---
# 15. GPUs and Distributed Training
LLMs are computational monsters.
Training requires clusters of GPUs like:
- NVIDIA H100
- A100
Training methods include:
- Data parallelism
- Tensor parallelism
- Pipeline parallelism
Frameworks:
- PyTorch
- DeepSpeed
- Megatron-LM
- JAX
Infrastructure becomes as important as model design.
---
# 16. Loss Functions and Optimization
The model learns using optimization algorithms like:
- AdamW
- SGD variants
Objective:
Minimize prediction loss.
Cross-entropy loss is commonly used for language modeling.
Smaller loss = better predictions.
---
# 17. Fine-Tuning
After pretraining, models are specialized.
Examples:
- Coding assistants
- Medical models
- Legal AI
- Customer support bots
Fine-tuning uses smaller curated datasets.
This adapts the base model to specific tasks.
---
# 18. RLHF: Reinforcement Learning From Human Feedback
This is what makes ChatGPT-like systems conversational.
Humans rank outputs.
The model learns preferences.
Pipeline:
```
Base Model
↓
Supervised Fine-Tuning
↓
Reward Model
↓
Reinforcement Learning
```
RLHF helps models become:
- Helpful
- Harmless
- Honest
---
# 19. Context Windows and Memory
Context window = how much text the model can "remember" during inference.
Examples:
- 4K tokens
- 32K tokens
- 128K+ tokens
Longer context requires advanced optimization because attention costs grow rapidly.
New techniques include:
- Flash Attention
- Sliding window attention
- Retrieval augmentation
---
# 20. Inference Optimization
Training is expensive.
Inference must be fast.
Optimization techniques include:
- Quantization
- KV caching
- Speculative decoding
- TensorRT
- Distillation
Goal:
Lower latency + lower cost.
---
# 21. Retrieval-Augmented Generation (RAG)
LLMs don't truly "know" everything.
So modern systems retrieve external knowledge dynamically.
Pipeline:
```
User Query
↓
Search Database
↓
Retrieve Relevant Chunks
↓
Inject Into Prompt
↓
Generate Response
```
This improves:
- Accuracy
- Freshness
- Enterprise applications
---
# 22. Mixture-of-Experts (MoE)
Modern frontier models increasingly use MoE architectures.
Instead of activating the entire model:
Only selected expert networks activate per token.
Benefits:
- Larger effective parameter counts
- Lower compute cost
- Better scaling efficiency
This is believed to be important in many modern systems.
---
# 23. AI Alignment and Safety
Raw models can produce harmful outputs.
Alignment layers help enforce:
- Safety
- Policy compliance
- Truthfulness
- Behavioral constraints
Techniques include:
- Constitutional AI
- RLHF
- Red teaming
- Adversarial testing
Alignment is now one of the hardest problems in AI.
---
# 24. The Real Challenge Isn't the Architecture
Most people think the hardest part is building the transformer.
It isn't.
The hardest parts are:
- Data quality
- Infrastructure
- Scaling
- Optimization
- Alignment
- Inference economics
The transformer paper was only the beginning.
The real engineering challenge is making these systems scalable and usable.
---
# 25. Final Thought
LLMs are one of the most important technological breakthroughs in modern history.
But they are not magic.
They are the result of:
- Mathematics
- Distributed systems
- Massive datasets
- Optimization engineering
- Human feedback loops
And we are still extremely early.
The next decade of AI will likely be defined by:
- Better reasoning
- Autonomous agents
- Multimodal systems
- Efficient architectures
- Real-time personalization
Understanding how LLMs are built is no longer optional for engineers.
It's becoming foundational knowledge for the future of technology.
---
**原推文链接**: https://x.com/shabnam_774/status/2058517919760355729