如何从零搭建 LLM 架构
来源:@shabnam_774 on X · 2026-05-24
深入剖析 OpenAI ChatGPT、Anthropic Claude 这类模型背后的系统
大多数人每天都在用 AI 模型。
但很少有人真正理解它们是怎么造出来的。
掀开盖子看,大语言模型(LLM)并不神奇。 它们是巨大的预测系统,用精心设计的神经网络架构在海量文本上训练出来。
但从零搭一个 LLM,远比"训练一个聊天机器人"复杂得多。
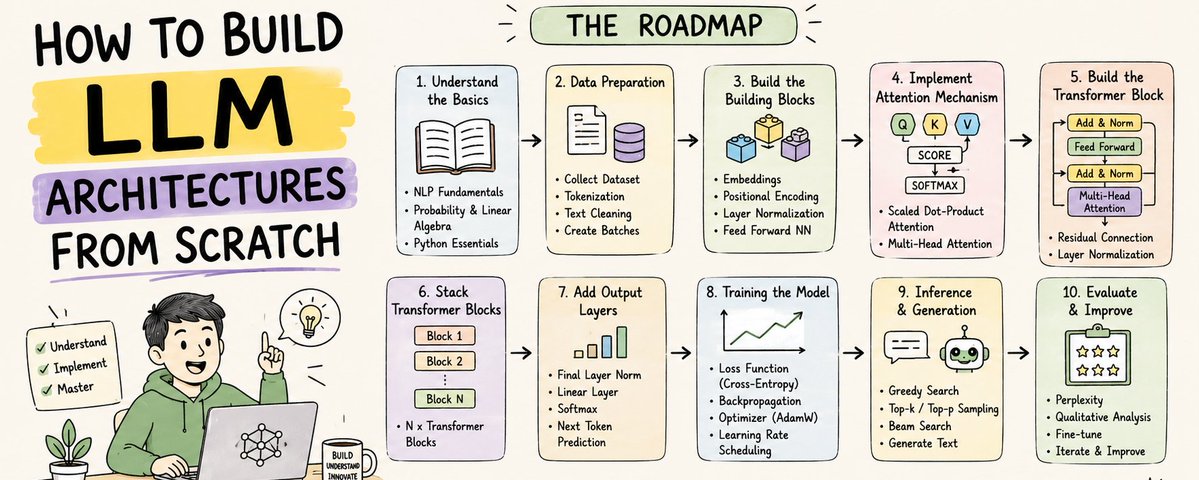
它涉及到:
- 数据工程(Data engineering)
- 分词(Tokenization)
- Transformer 架构
- 分布式训练(Distributed training)
- GPU 优化
- 强化学习(Reinforcement learning)
- 推理系统(Inference systems)
- 对齐层(Alignment layers)
- 内存优化
这篇文章会一步步把现代 LLM 的完整架构拆开讲,尽量做到实用、能看懂。
1. 什么是 LLM?
大语言模型是一个被训练来在序列中预测下一个 token 的神经网络。
举例:
输入:
"The future of AI is"
模型预测:
"transformative"
然后一个 token 接一个 token 继续往下预测。
这就是这些系统的根基:
- OpenAI GPT 系列
- Anthropic Claude
- Google Gemini
- Meta Llama
在足够大的规模下,这个看似简单的预测过程会变得极其强大。
2. 搭建 LLM 的核心流水线
完整流程长这样:
Raw Internet Data
↓
Cleaning + Filtering
↓
Tokenization
↓
Transformer Architecture
↓
Pretraining
↓
Fine-Tuning
↓
RLHF / Alignment
↓
Inference Optimization
↓
Deployment
每一个阶段都重要。
数据弱了或者架构设计差了,整个模型都会被毁掉。
3. 第一步:数据采集
LLM 需要海量数据集。
现代前沿模型训练在:
- 书籍
- 维基百科
- 研究论文
- 网页
- 代码仓库
- 文档
- 对话
- 论坛
数据来源可能包括:
- Common Crawl
- GitHub
- ArXiv
- Stack Overflow
- 公开数据集
目标是 多样性 + 规模。
一个用优质数据训练的小模型,常常能打败用噪声数据训练的大模型。
4. 数据清洗与过滤
互联网原始数据是混乱的。
你必须剔除:
- 垃圾内容(Spam)
- 重复数据
- 低质量文本
- 有毒内容
- 排版破损
- 重复序列
- AI 生成的垃圾
这一步被严重低估。
公司在数据质量上砸下巨额资源,因为:
更好的数据 > 更大的模型
常见过滤方法:
- 去重(Deduplication)
- 启发式过滤(Heuristic filtering)
- 质量打分(Quality scoring)
- 语种检测(Language detection)
- 安全过滤(Safety filtering)
- NSFW 过滤
5. 分词:把文本变成数字
神经网络看不懂单词。
它们只懂数字。
所以文本要先变成 token。
举例:
"ChatGPT is powerful"
↓
[1532, 4021, 318, 7821]
这个过程叫做 tokenization(分词)。
主流的分词方法:
- BPE(Byte Pair Encoding)
- SentencePiece
- WordPiece
Token 可以表示:
- 单词
- 子词(Subwords)
- 字符
- 标点
高效的分词方案对性能和成本影响巨大。
6. Embedding:给 Token 赋予含义
Token 会被转换成向量。
向量本质上是一串表示语义含义的数字。
举例:
King → [0.2, -0.8, 1.4, ...]
Queen → [0.3, -0.7, 1.5, ...]
含义相近的概念在向量空间里彼此靠近。
这就是模型学习单词关系的方式。
Embedding 是语义理解的基础。
7. Transformer 架构
它改变了一切。
Transformer 架构出自那篇里程碑式论文:
Google Brain 研究者于 2017 年发表的 "Attention Is All You Need"。
Transformer 取代了更老的系统:
- RNN
- LSTM
因为它的扩展性远胜以往。
如今几乎所有现代 LLM 都跑在 Transformer 架构之上。
8. 自注意力:LLM 的心脏
自注意力(Self-attention)让模型决定:
在当前语境中,哪些词最重要。
举例:
"The animal didn't cross the street because it was tired."
模型学到:
"it" 指的是 "animal"
而不是 "street"。
自注意力会动态地给 token 之间的关系打权重。
这才让上下文理解成为可能。
9. 理解 Q、K、V(Query, Key, Value)
注意力机制依靠:
- Query 向量
- Key 向量
- Value 向量
把它想象成搜索。
每个 token 都在问:
"其他哪些 token 跟我相关?"
然后注意力分数决定其重要性。
公式:
Attention(Q,K,V) = softmax(QKᵀ / √dₖ)V
这是现代 AI 中最重要的方程之一。
10. 多头注意力(Multi-Head Attention)
不是只用一个注意力机制:
LLM 同时使用多个注意力头。
每个头学习不同种类的关系:
- 语法
- 逻辑
- 句法
- 上下文
- 长距离依赖
这极大地提升了表征学习能力。
11. 位置编码(Positional Encoding)
Transformer 是并行处理 token 的。
但语言是有顺序的。
所以模型需要位置信息。
举例:
Dog bites man
Man bites dog
字一样,含义完全相反。
位置编码帮助模型理解序列结构。
12. 前馈网络(Feed Forward Networks)
经过注意力层之后,token 会进入前馈神经网络。
这些层负责:
- 精炼表征
- 提升非线性
- 增强推理能力
一个 transformer block 通常包含:
Attention
↓
Normalization
↓
Feed Forward Network
↓
Normalization
这个块会被堆叠几十甚至上百次。
13. 缩放定律(Scaling Laws)
AI 领域的一个重大发现:
用更多数据训练更大的模型,性能通常会更好。
缩放包括:
- 更多参数
- 更多 token
- 更多算力
例子:
- GPT-2 → 15 亿参数
- GPT-3 → 1750 亿参数
现代前沿系统可能用上万亿参数(有时通过 Mixture-of-Experts 实现)。
14. 训练模型
训练就是调整权重,让预测误差最小化。
流程:
Input sentence
↓
Predict next token
↓
Compare prediction vs actual token
↓
Calculate loss
↓
Backpropagation
↓
Update weights
这个过程会重复几十亿次。
训练大模型可能需要:
- 数千张 GPU
- 几周到几个月
- 庞大的分布式系统
15. GPU 与分布式训练
LLM 是计算怪兽。
训练需要的 GPU 集群,比如:
- NVIDIA H100
- A100
训练方法包括:
- 数据并行(Data parallelism)
- 张量并行(Tensor parallelism)
- 流水线并行(Pipeline parallelism)
框架:
- PyTorch
- DeepSpeed
- Megatron-LM
- JAX
基础设施和模型设计本身一样重要。
16. 损失函数与优化
模型靠以下优化算法学习:
- AdamW
- SGD 变种
目标:
最小化预测损失。
语言建模常用 cross-entropy loss(交叉熵损失)。
损失越小 = 预测越准。
17. 微调(Fine-Tuning)
预训练完之后,模型还要被专业化。
例子:
- 编程助手
- 医疗模型
- 法律 AI
- 客服机器人
微调使用更小、经过精挑细选的数据集。
它把基础模型适配到具体任务上。
18. RLHF:基于人类反馈的强化学习
这是让 ChatGPT 这类系统变得"会聊天"的关键。
人类对输出排序。
模型学习人类的偏好。
流程:
Base Model
↓
Supervised Fine-Tuning
↓
Reward Model
↓
Reinforcement Learning
RLHF 帮助模型变得:
- 有帮助(Helpful)
- 无害(Harmless)
- 诚实(Honest)
19. 上下文窗口与记忆
上下文窗口 = 模型在推理时能"记住"的文本量。
例子:
- 4K tokens
- 32K tokens
- 128K+ tokens
更长的上下文需要更进阶的优化,因为注意力的开销增长非常快。
新技术包括:
- Flash Attention
- 滑动窗口注意力(Sliding window attention)
- 检索增强(Retrieval augmentation)
20. 推理优化
训练昂贵。
推理则必须够快。
优化技术包括:
- 量化(Quantization)
- KV 缓存(KV caching)
- 投机解码(Speculative decoding)
- TensorRT
- 蒸馏(Distillation)
目标:
更低的延迟 + 更低的成本。
21. 检索增强生成(RAG)
LLM 并不真的"知道"一切。
所以现代系统会动态地检索外部知识。
流程:
User Query
↓
Search Database
↓
Retrieve Relevant Chunks
↓
Inject Into Prompt
↓
Generate Response
这能改善:
- 准确性
- 时效性
- 企业级应用能力
22. 专家混合(Mixture-of-Experts,MoE)
现代前沿模型越来越多地采用 MoE 架构。
不是激活整个模型:
而是每个 token 只激活被选中的专家网络。
好处:
- 更大的有效参数规模
- 更低的算力开销
- 更好的扩展效率
这被认为对许多现代系统至关重要。
23. AI 对齐与安全
原始模型可能产出有害输出。
对齐层的作用是强制:
- 安全
- 政策合规
- 真实性
- 行为约束
技术手段包括:
- Constitutional AI(宪法式 AI)
- RLHF
- 红队测试(Red teaming)
- 对抗性测试(Adversarial testing)
对齐如今是 AI 中最难的问题之一。
24. 真正的难题不是架构
大多数人以为最难的部分是搭出 Transformer。
并不是。
最难的部分其实是:
- 数据质量
- 基础设施
- 规模化
- 优化
- 对齐
- 推理经济性
那篇 Transformer 论文只是开始。
真正的工程难题,是把这些系统做到可扩展、可使用。
25. 收尾
LLM 是现代史上最重要的技术突破之一。
但它们不是魔法。
它们是以下要素叠加的结果:
- 数学
- 分布式系统
- 海量数据集
- 优化工程
- 人类反馈循环
而我们仍处于极早期。
未来十年的 AI 大概率会被这些方向塑造:
- 更强的推理
- 自主 agent
- 多模态系统
- 更高效的架构
- 实时个性化
理解 LLM 是怎么造出来的,对工程师而言已不再是可选项。
它正在成为面向未来技术的基础知识。